Hash Tables
A hash table is a data structure that implements a map.
It uses an array to store key-value pairs, and a hash function that, given a key, computes an index into the array where the associated value can be found.
Operations
- Insert: Insert or replace key-value pair
- Lookup: Given a key, get its associated value
- Delete: Given a key, delete its key-value pair
Performance
- Average-case: O(1)
- Assuming good hash function and appropriate resizing
- Worst-case: O(n)
- If all keys hash to the same value (extremely unlikely with good hash)
Hashing
Hashing is the process of mapping data of arbitrary size to fixed-size values using a hash function
A hash function:
- Maps a key to an index in the range [0, N − 1]
- where N is the size of the array
- Must be cheap to compute
- Is deterministic
- Given the same key, will always return the same index
- Ideally, maps keys uniformly over the range of indices
A hash collision occurs when for two keys x and y, x $\neq$ y, but h(x) = h(y).
Collision Resolution
Important statistic: load factor (α)
- Ratio of items to slots; α = M/N
- Useful when analysing collision resolution methods
Separate Chaining
Resolve collisions by having multiple items per array slot. Each array slot contains a linked list of items that are hashed to that index.
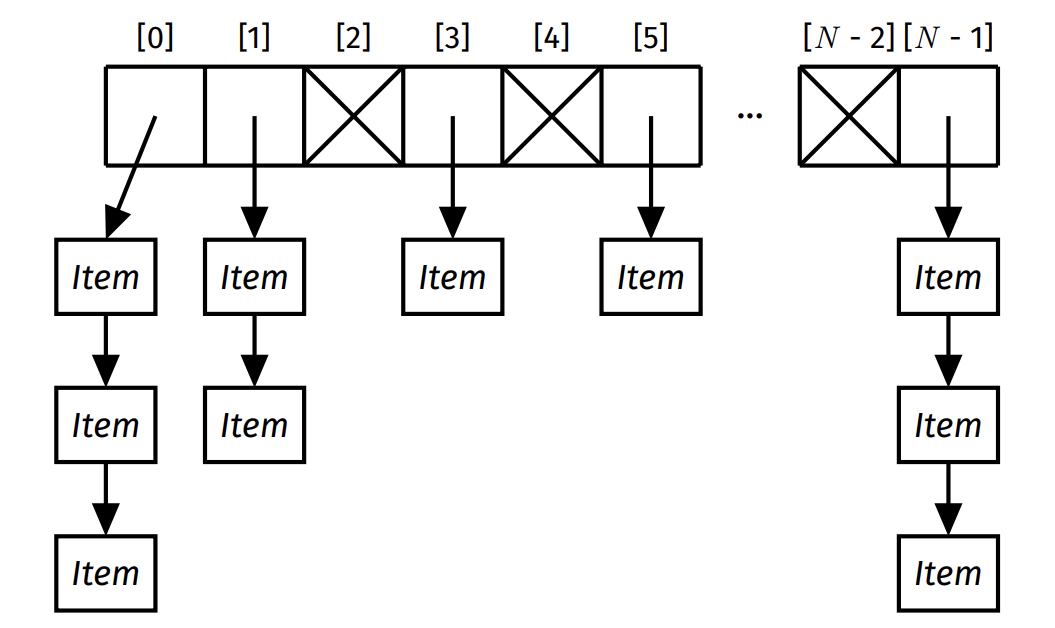
Cost analysis:
- N array slots, M items
- Average list length L = M/N
- Best case: Items evenly distributed, so maximum list length is $\lceil M/N \rceil$
- Cost of insert/lookup/delete: $O(M/N)$
- Worst case: One list of length M
- Cost of insert/lookup/delete: $O(M)$
Average costs:
- If good hash and α ≤ 1, cost is $O(1)$
- If good hash and α > 1, cost is $O(M/N)$
- To avoid degrading perfomance, hash table should be resized when α ≈ 1
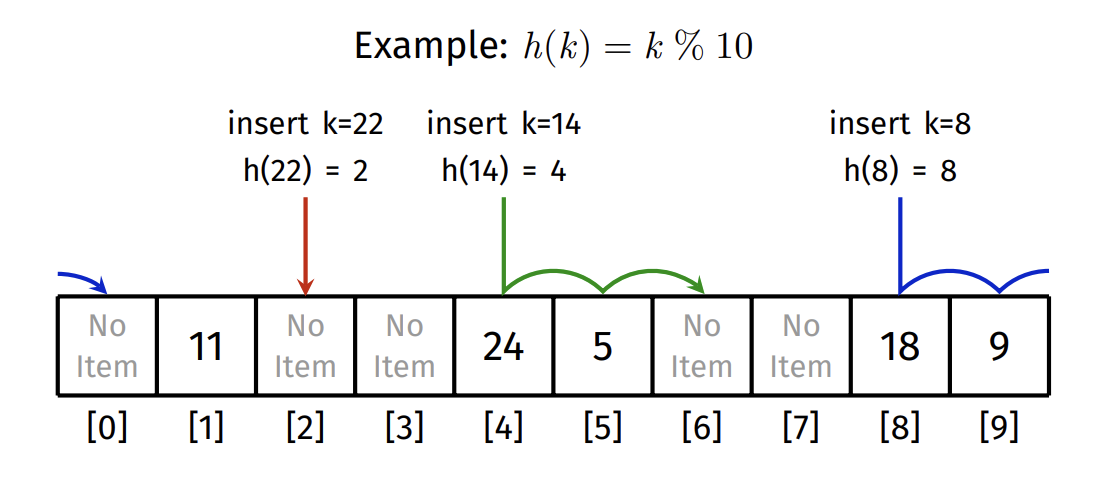
Linear Probing
Resolve collisions by finding a new slot for the item
- Each array slot stores a single item (unlike separate chaining)
- On a hash collision, try next slot, then next, until an empty slot is found
- Insert item into empty slot
Two primary methods for deletion:
- Backshift
- Remove and re-insert all items between the deleted item and the next empty slot
- Tombstone
- Replace the deleted item with a “deleted” marker (AKA a tombstone) that:
- Is treated as empty during insertion
- Is treated as occupied during lookup
Backshift method:
- Moves items closer to their hash index
- Thus reducing the length of their probe path
- Deletion becomes more expensive
Tombstone method:
- Fast
- But does not reduce probe path length
- Large number of deletions will cause tombstones to build up
Problem with linear probing: clustering
- Items tend to cluster together into long runs
- Long runs are a problem:
- Insertions must travel to the end of a run
- Lookups of non-existent keys must travel to the end of a run
Double Hashing
Double hashing improves on linear probing:
- By using an increment which…
- is based on a secondary hash of the key
- ensures that all slots will be visited (by using an increment which is relatively prime to N)
- Tends to reduce clustering ⇒ shorter probe paths
To generate relatively prime number:
- Set table size to prime, e.g., N = 127
- Ensure secondary hash function returns number in range [1, N − 1]
Summary of Collision Resolution
Collision resolution approaches:
- Separate chaining: Easy to implement, allows α > 1
- Linear probing: Fast if α << 1, complex deletion
- Double hashing: Avoids clustering issues with linear probing
All approaches can be used to achieve O(1) performance on average, assuming
- good hash function
- table is appropriately resized if load factor exceeds threshold
Implementation Details
How do we resize a hash table?
- Hash function depends on the number of slots
- Items may not belong at the same index after resizing
- So all items must be re-inserted
- Good strategy is to roughly double the number of slots every resizing