Tries
A trie:
- is a tree data structure
- used to represent a set of strings
- e.g., all the distinct words in a document, a dictionary, etc.
- we will call these strings keys or words
- supports string matching queries in $O(m)$ time
- where $m$ is the length of the string being searched for
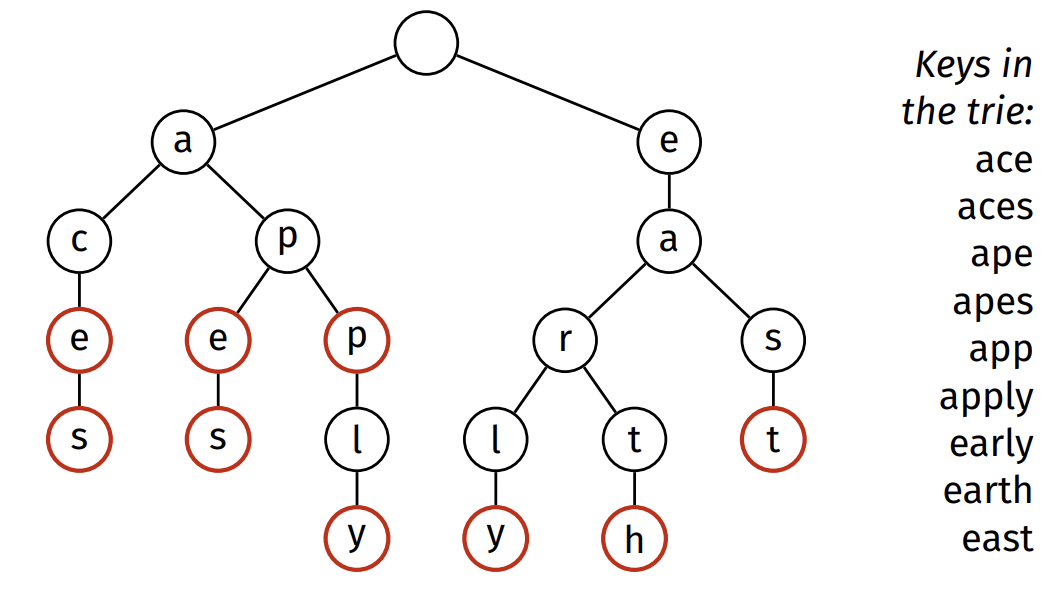
Important features of tries:
- Each link represents an individual character
- A key is represented by a path in the trie
- Each node can be tagged as a “finishing” node
- A “finishing” node marks the end of a key
- Each node may contain data associated with key
- Unlike a search tree, the nodes in a trie do not store their associated key
- Instead, keys are implicitly defined by their position in the trie\
Representation
Assuming alphabetic strings:
#define ALPHABET_SIZE 26
struct node {
struct node *children[ALPHABET_SIZE];
bool finish; // marks the end of a key
Data data; // data associated with key
};Trie Insertion
Process for insertion:
- Start at the root
- For each character $c$ in the key (from left to right):
- If there is no child node corresponding to $c$, create one
- Descend into the child node corresponding to $c$
- Mark the resulting node as a finishing node and insert data (if any)
trieInsert(t, key, data):
Input: trie t,
key of length m and associated data
Output: t with key and data inserted
if t is empty:
t = new node
if m = 0:
t->finish = true
t->data = data
else:
first = key[0]
rest = key[1..m - 1] // i.e., slice off first character from key
t->children[first] = trieInsert(t->children[first], rest, data)
return tTrie Search
Search is similar to insertion:
- Start at the root
- For each character $c$ in the key (from left to right):
- If there is no child node corresponding to $c$, return false
- Descend into the child node corresponding to $c$
- If the resulting node is a finishing node, then return true, otherwise return false
trieSearch(t, key):
Input: trie t,
key of length m
Output: true if key is in t, false otherwise
if t is empty:
return false
else if m = 0:
return t->finish = true
else:
first = key[0]
rest = key[1..m - 1]
return trieSearch(t->children[first], rest)Trie Deletion
Process for deletion:
- Find node corresponding to given key
- If node doesn’t exist, do nothing
- Mark the node as a non-finishing node
- While current node is not a finishing node and has no child nodes:
- Delete current node and move up to parent
- Handled recursively
- Do not delete the root node!
- Delete current node and move up to parent
trieDelete(t, key):
Input: trie t,
key of length m
Output: t with key deleted
return doTrieDelete(t, key, true)
doTrieDelete(t, key, isRoot):
Input: trie t,
key of length m,
boolean isRoot indicating if t is the root node
Output: t with key deleted
if t is empty:
return t
else if m = 0:
t->finish = false
else:
first = key[0]
rest = key[1..m - 1]
t->children[first] = doTrieDelete(t->children[first], rest, false)
if isRoot = false and t->finish = false and t has no child nodes:
return NULL
else:
return tAnalysis
Analysis of standard trie:
- $O(m)$ insertion, search and deletion
- where $m$ is the length of the given key
- each of these needs to examine at most m nodes
- $O(nR)$ space
- where $n$ is the total number of characters in all keys
- where $R$ is the size of the underlying alphabet (e.g., 26)
Variants
Different representations exist to reduce memory usage at the cost of increased running time:
- Use a singly linked list to store child nodes
- Alphabet reduction - break each character into smaller chunks, and treat these chunks as the characters
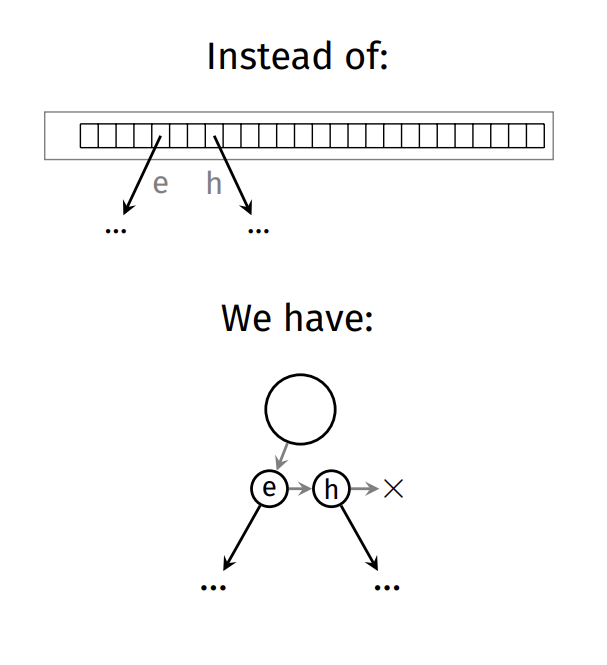
Linked list of children
Have each node store a linked list of its children instead of an array of ALPHABET_SIZE pointers
struct node {
struct child *children;
bool finish;
Data data;
};
struct child {
char c;
struct node *node;
struct child *next;
};
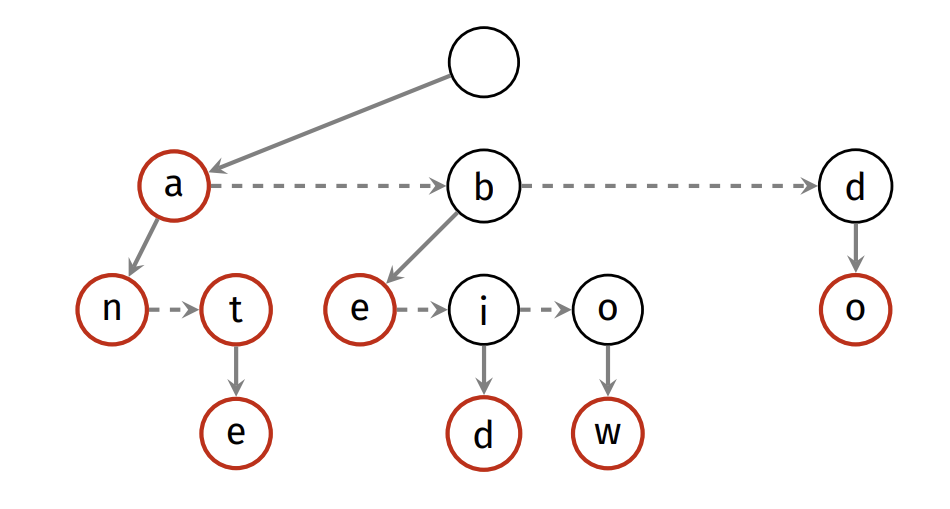
We can simplify this representation by merging each linked list node with its corresponding trie node This produces the left-child right-sibling binary tree representation
struct node {
char c;
struct node *children;
struct node *sibling;
bool finish;
Data data;
};
Analysis:
- This representation uses much less space
- Each node just stores one extra pointer to its sibling instead of ALPHABET_SIZE pointers
- But this is at the expense of running time
- Need to traverse up to ALPHABET_SIZE nodes before reaching desired child
Alphabet Reduction
Break each 8-bit character into two 4-bit nybbles
This reduces the branching factor, i.e., the number of pointers in each node

Analysis:
- This representation uses much less space
- Much fewer pointers per node
- But this is at the expense of running time
- Path to each key is twice as long - lookups need to visit twice as many nodes
Compressed Tries
In a compressed trie, each node contains ≥ 1 character
Obtained by merging non-branching chains of nodes
Specifically, non-finishing nodes with only one child are merged with their child